Весна началась, а значит, пришло время навести порядок … и не только дома, но и в SEO. Приказы, о которых я собираюсь написать, должны быть выполнены в начале работы над страницей, чтобы исключить каждый, даже самый маленький элемент, который впоследствии может помешать нам в достижении цели. Давайте перейдем к делу.
Чтобы проверить статус индексации наших страниц, мы будем использовать базовую команду каждого SEO, то есть сайта . Я сразу отмечаю, что Google строго ограничивает количество подстраниц, отображаемых для общего запроса в форме site: domain.pl, и гораздо больше информации можно найти, уточнив запрос, добавив в него еще один элемент. Например, запрос site: lexy.com.pl возвращает сообщение о количестве подстраниц около 1500, тогда как после нажатия на все результаты их остается только 231. Если я добавлю « inurl: html » к запросу (такие подсказки содержат сообщения в блоге), будет отображать 228 из них, при этом исключая подстраницы из .html (» -inurl: html «) их будет 68, что дает в общей сложности 296. Второй пример — запрос сайта: lexy.com.pl/blog/tag возвращает только 48 результатов, в то время как изменение этой записи для следующего: site: lexy.com.pl/blog/ inurl: тег будет отображать до 78.
Первоначально, когда нам необходимо общее понимание того, что находится в выдаче, достаточно общего запроса сайта для данного домена. Мы уточняем их только для проблемных подстраниц, чтобы получить более полный список.
Что мы можем найти в списке проиндексированных нами подстраниц сайтов, проанализированных нами?
- разные версии адресов , то есть с www и без www, с HTTP и HTTPS — мы проверим их после ввода запросов в форме:
- « Сайт: www.domena.pl » (адреса от www), « site: domain.pl — онлайн: www » или « site: domain.pl — сайт: www.domena.pl » (адреса без www);
- « Site: domain.pl inurl: http » (адреса из HTTP), « site: domain.pl inurl: https » или « site: domain.pl -inurl: http » (адреса из HTTPS). Примечание — запрос в виде « site: https: //domain.pl » здесь не будет работать;
- Субдомены неожиданности — с помощью команды » site: domain.pl — site: www.domena.pl » мы проверим все проиндексированные субдомены. Может оказаться, что мы найдем там рабочие субдомены, то есть субдомены, используемые для рабочей версии сайта, а также дополнительные магазины, блоги и другие страницы, о которых мы должны быть проинформированы в начале сотрудничества. Давайте помнить, что грехи поддоменов могут влиять на состояние всех сайтов в пределах одного домена, поэтому, в частности, при анализе уменьшения позиции обращайте внимание на то, какой из поддоменов был виноват;
- возврат неожиданных подстраниц 404 — этот тип подстраниц может нанести большой ущерб, когда речь идет об уменьшении позиции на сайте. Внезапно, каждый день появляются сотни подстраниц, которые никогда не должны появляться, потому что они никогда не существовали физически. Это может быть результатом действий конкурентов, и хуже всего то, что им сложно управлять, потому что простой блокады в файле robots.txt здесь недостаточно;
- результаты поиска , например, » site: domain.com/search » — вам нужно проверить сайт, чтобы увидеть, какой адрес появляется после использования поисковой системы, чтобы узнать, какой фрагмент ввести в Google. » Помните, что Google игнорирует символы «?», Которые часто появляются в адресе страницы непосредственно перед поисковой фразой, поэтому в командах Google вам нужно использовать фрагменты адресов, которые не будут игнорироваться;
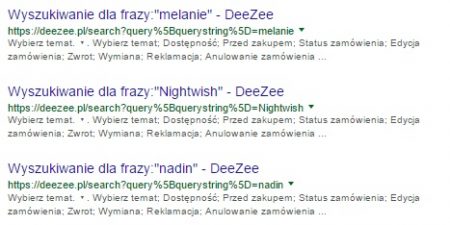
- результаты сортировки , например, » site: domain.pl inurl: sort » Также в этом случае не забудьте игнорировать знак вопроса, который не следует использовать в запросах Google. Вот почему в этом случае мы будем использовать фрагмент « site: domain.pl », указывающий, какой домен нам интересен, и « inurl: sort », указывающий, что мы ищем адреса с этим параметром, отвечающим за сортировку результатов;
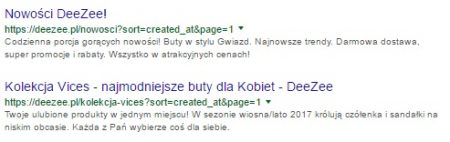
- фильтрация результатов , например, » site: domain.pl inurl: price «;
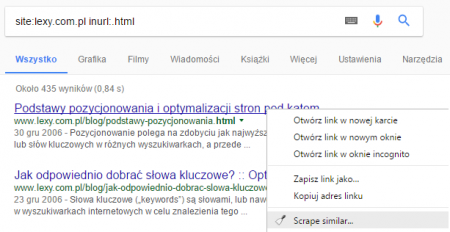
- Старая структура URL — чтобы быстро это проверить, стоит использовать, например, надстройку Google Chrome Scraper, которую я описал в пункте 3 списка интересных инструментов . Это позволит нам экспортировать список проиндексированных адресов, который мы затем проверим в инструменте www.urlitor.com и вернем информацию о том, какие из них имеют набор перенаправления 301, а какие возвращают 404 — последний заинтересует нас больше всего;
- автоматически генерируемые подстраницы — здесь сложно указать конкретный запрос, потому что каждый случай будет индивидуальным. Это касается, среди прочего o подстраницы, созданные с помощью дыр в скриптах;
- URL комментариев , например » inurl: fb_comment_id «;
- адреса помеченных ссылок , например, » inurl: utm_medium «;
- адреса, содержащие #! например, » inurl: _escaped_fragment «;
- другие — например, печатные версии, PDF-версии опубликованных статей, адреса с идентификаторами сеансов.
Что именно не так с индексацией этих типов адресов? Почему так важно очистить индекс?
Прежде всего, Google не хочет дубликатов в своем индексе, и они создаются, если один и тот же контент доступен по разным адресам, например, по адресу www, без www и т. Д. Проблема касается как копий 1: 1, так и ситуаций, в которых большая часть информации по одному адресу совпадает с той, которая доступна по другим адресам, то есть в результатах поиска или другого типа фильтрации или сужения представленной информации. Это не только увеличивает риск того, что Google плохо оценит весь веб-сайт, рассматривая большую часть подстраниц как дублирующийся контент или тонкий контент, но также вызывает проблему с каннибализацией ключевых слов — это происходит, когда поисковая система не уверена в этом , который среди нескольких адресов является более релевантным результатом для искомой фразы.
У нас есть много возможностей, когда дело доходит до контроля того, что находится в индексе. Если вам не нужны некоторые подстраницы, у нас есть несколько решений, например:
- установка перенаправления 301 или использование rel = «canonical» для адреса назначения, но в некоторых случаях также стоит использовать опцию для установки предпочитаемого домена в консоли поиска . 301 и canonical дадут почти одинаковый эффект, когда речь идет о самих поисковых системах, потому что оба решения должны приводить к передаче мощности, передаваемой по ссылкам, и, таким образом, приводить к захвату позиции по адресу назначения. Основное отличие состоит в том, что 301 также работает с пользователями, перенаправляя их на другой адрес, в то время как non-seo не заметит канонического. С другой стороны, установка предпочтительного домена была бы скорее предложением, ожидая гораздо более слабого эффекта, чем 301 или канонический;
- удаление выбранных подстраниц из индекса через консоль поиска, в частности, Google Index -> Удалить URL-адреса . Вы можете индексировать один адрес или даже целую папку за один раз. Теоретически, если к указанным подстраницам или метатегу noindex (или ни одному , т.е. noindex + nofollow ) не применен ни один блок доступа, такие подстраницы могут возвращаться к индексу, поэтому Google считает, что это инструмент для временного удаления страниц из индекса. Примечание: не случайно индексировать всю страницу 😉
- установка блока доступа робота к выбранным разделам страницы с помощью соответствующей записи в файле robots.txt — я просто обращаю внимание на тот факт, что блокада в файле robots.txt не будет индексировать страницу, а только запретит роботам входить на нее и загружать ее содержимое для сохранения копии. ;
- установка nofollow в ссылках на подстраницы, которые не должны посещать поисковые системы — использование этого решения не гарантирует, что страница не попадет в индекс, даже более того, если она уже есть в нем. Nofollow поможет контролировать посещения роботов, потому что они сосредоточатся на посещении страниц по ссылкам dofollow и пропустят те, которые отмечены атрибутом nofollow . Если эти подстраницы еще не проиндексированы, и никакие внешние источники не ссылаются на них ссылками dofollow или каким-либо другим образом никто не помог им добраться до Google, такие подстраницы не должны появляться в индексе;
- физическое удаление подстраниц — если необходимо полностью избавиться от некоторых подстраниц, обратите внимание на то, чтобы установить соответствующий статус, то есть 404 или 410, а не 200 с отображаемым сообщением об отсутствии результата — это так называемое мягкий (или очевидный) 404.















