Время для еще одной записи в серии SEO отражения. Это следует из разговора о FB, в котором были сделаны заявления, в частности о том, что SQT вообще не читает содержание запросов на повторное рассмотрение, что даже удаленные ссылки должны быть добавлены для дезавуирования вместо, например, проверки связи и т. д. — больше никаких подробностей. Я напишу, как я подхожу к теме анализа ссылок и отправки RR .
![]()
Этап 1 — анализ ссылок
Некоторые настаивают на том, что данных GWT достаточно для анализа ссылок . Однако среди них есть люди, которым потребовалось очень много времени, чтобы попытаться снять фильтр, поэтому для меня это предположение, что это может быть не совсем правильно. Ну, сами Гуглар предлагают полагаться только на свои данные, но думаете ли вы, что они могут указать на коммерческий инструмент, с которым они не работают? 😉 Помните, что в примерах неестественных ссылок, которые нам дает Google, иногда вы можете найти их за пределами базы в GWT . Это, в свою очередь, говорит о том, что данные, видимые нам в GWT, представляют собой лишь часть данных, собранных поисковой системой. В любом случае, давайте нарисуем отчеты из нескольких инструментов и посмотрим, как из недели в неделю GWT-ссылки, некоторые из которых уже были найдены другим программным обеспечением.
Почему бы не подойти к анализу более всесторонне, дополнив эти данные отчетами из таких инструментов, как Majestic SEO или Ahrefs ? Оба имеют возможность генерировать бесплатный отчет для проверенных доменов — в Majestic это немного сбивает с толку, так что здесь вы можете найти инструкцию , в Ahrefs этой вкладки достаточно.
Преимущество этих инструментов, которое многие недооценивают, заключается в том, что они немедленно дают нам полные данные о целевой странице, привязке и многих других параметрах, которые данные GWT нам не дают. Поэтому, чтобы подготовить файл к анализу, я рекомендую собрать все эти данные в один файл, добавить столбец с именем домена (оно будет необходимо для сортировки), скопировать столбец с адресами ссылок на него, а затем использовать функцию Excel, которая позволяет сократить адреса страниц с полных до только домены.
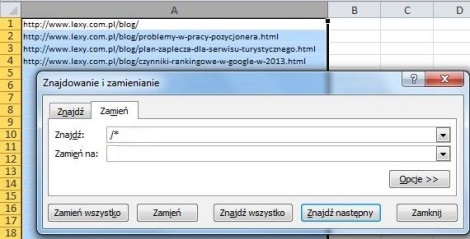
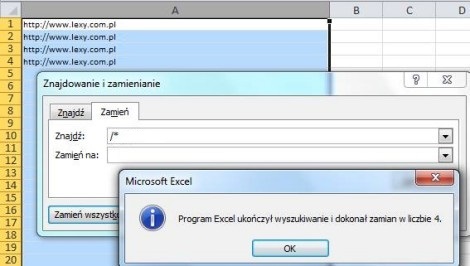
Давайте также удалим « www » из ссылок и заменим http: // на domain: чтобы после анализа вы могли поместить некоторые ссылки в отдельный файл disavow.
Основываясь на таких подготовленных данных, достаточно проанализировать буквально 1 ссылку на домен , даже не посещая много страниц (якоря часто говорят сами за себя, а на некоторых связанных страницах вы можете сразу же загрузить 404 и пропустить анализ ссылок, ведущих к ним), что нам потребуется делать с данными только в виде адресов сайтов. Подробности о том, как анализировать ссылки, уже были описаны в статье « Как распознать токсичные ссылки », поэтому давайте продолжим.
Этап 2 — Мероприятия
По своему опыту я знаю, что приложения, в которых анализ был выполнен правильно, отклоняются, но файл ограничен отправкой средства удаления нежелательных ссылок . Я использовал один и тот же файл несколько раз, без добавления новых ссылок, пойманных инструментами, но только после удаления некоторых из них удалось удалить фильтр. Мне было ясно, что я должен показать попытки исправить ситуацию, а не ограничиваться анализом и дезавуацией. По моему мнению, физическое удаление является более важным, и дезавуирование — только последнее средство для ссылок, которые не могут быть удалены.
Поэтому, чтобы иметь шанс на успешное рассмотрение заявки, вы должны показать свои попытки организовать профиль ссылки, а не просто загрузить файл и рассчитывать на решение вопроса таким способом. Помните, что с другой стороны есть человек, сосредоточенный на руководящих принципах, который хочет, по крайней мере, надеяться, что мы сделаем выводы из нашего промаха. Давайте поставим себя на его место — если мы хотим достичь цели, например, изменить стратегию связывания, оставим ли мы эту тему слегка, или мы хотим быть уверены в запланированных изменениях? Да, это что-то вроде признания в своих грехах и многообещающего улучшения
Этап 3 — очередь на модерацию
Именно здесь я основываю большинство на принципе «я думаю».
Я начну с того, что гугларийцы гарантируют, что приложения действительно читаются и что их следует применять. Однако где-то однажды я наткнулся на утверждение, что некоторые приложения отклоняются автоматически, и, вероятно, большинство из нас в Google будет пытаться автоматизировать целое хотя бы частично.
На мой взгляд, процедура обработки заявки может проходить полуавтоматически . Как бы это выглядело? Например, когда Google получает наш отчет, он автоматически проверяется и проверяется, были ли предприняты какие-либо действия и, если да, достаточны ли они для того, чтобы отчет доходил до сотрудника, — в конце концов машина может быть неправильной. , Затем сотрудник оценивает, может ли он удалить фильтр или нет.
Машина не должна работать с первым приложением, потому что тогда вы не можете сообщить, например, что ссылки были добавлены конкурсом или что вы купили использованный домен — такие приложения будут отклонены без остановки. Может быть, он работает либо на последующих приложениях в дополнение к первому, либо на страницах или учетных записях, которые уже каким-то образом уже свернуты, например, существует множество отфильтрованных или даже заблокированных страниц, связанных с данной учетной записью, или это довольно новая учетная запись.
Однако, если такой машины не существует, что может быть в результате отклонения некоторых приложений без их чтения? Я не хотел бы верить в случайность таких действий. Что вы думаете об этом?

















